| The Intelligence of
Document Tagging |
Our
experiences in AI shows that machines are not going to
make us redundant, but that they will augment the human
workforce. AI as a technology has only solved half of
the equation. AI technology has had to be contextualized
in the domain of an industry, information that only
humans have possessed. Therefore, people who can apply
their knowledge and experience in meaningful ways with
AI will be increasingly important.
Human beings possess the
ability to process experience, knowledge, intuition and
common sense for appropriate critical outcomes. When it
comes to surfacing accurate, contextualized highlight
information - meta tags, synopsis, annotations,
labels... human beings are not the only resource and now
may not even be the right resource. After all, as human
beings we are all influenced by our own experiences and
surroundings which infuses bias and how we understand
information. To provide high quality highlight details -
key phrases, keywords, text labels, text annotations,
content tags and the like - for these data tags to be
truly useful, they must be objective and unbiased.
Being able to process
Yotabytes of content with pure objectivity (zero bias)
is where AI and Machine Learning come to the fore. Of
course it's possible to amass hundreds, even thousands
of Text Labeling / Analytics specialists, however, the
way one person understands a document is quite often
different from how another person interprets that same
textual content. Compound that bias with the volumes of
content does make for an extremely daunting task,
especially if the content has already been published
without an authors contextual key phrase tags. This is
where an AI and Machine Learning infused technology such
as Doc-Tags, powered by the patent-backed xAIgent API,
enhances our human processes. Take this type of AI + ML
technology and give it the capability to parse Text
Labels, Key Phrases, Text Annotations, Tags, from any
text-based content, of any subject matter with results
having contextual relevance and high accuracy gives us a
whole new world of objective understanding at our finger
tips.
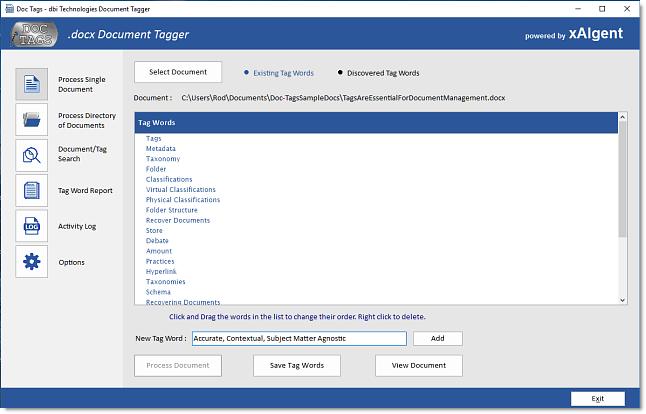
Doc-Tags is a free to use
Windows application engineered to process Text files and
Word Documents, out of the 'box', exposing each
document's key phrases (Tags) with contextually relevant
accuracy. The Key Phrase results (Tags) of each
document's processing are placed automatically into the
documents profile Tag Property giving the Doc-Tags'
processed document a high degree of relevance with
contextual accuracy - the ultimate goal of any Content /
Document Management System.
Not only will Doc-Tags give
any textual content a high-level and immediate,
accurate, contextual relevance, Doc-Tags may be set to
process individual files or directories of files with
each document processed logged in its database along
with the Key Phrase Tag results for quick referential
services. Which documents contain these keywords / key
phrases used in this manner? Search and Compare files
and directories of files for keywords and key phrases
(Tags) using Doc-Tags' built-in reporting. Or, customize
your own reports using the Doc-Tags XML Database.
A whole new world of
document insight is at your finger tips...
https://www.Doc-Tags.com |
|
|
|
| |
|
|
 |
|
|
|
|
|
|
 |
|
|
| |
| Today is the last day you
read / re-read a document to define it for an Enterprise
Content Management System or to publish content on the
Semantic Web |
| |
|
|
|
|
|
 |
|
|
|
|
|
| |
|
|
|
Feature
Highlights:
|
|
| |
• Automatically Create Contextually Accurate Tags
for a Document
|
| |
• Automatically Create
Contextually Accurate Tags Document Folder
|
| |
• Automatically Add Document Meta Data Tags
|
| |
• Subject Domain
Agnostic - additional training NOT required
|
| |
• Automatic Processing - supervision is NOT
required
|
| |
• Document Tags are presented by Weighted
Importance
|
| |
• Process Reporting ...
|
| |
• Tags Generated
|
| |
• Documents Processed
|
| |
• Document Location
|
| |
• Examine Comparative Document Tags
|
| |
• Find Documents with 'These' Tags
|
| |
• Multi Language Support ...
|
| |
• English
|
|
• French
|
| |
• German
|
| |
• Japanese
|
| |
• Korean
|
| |
• Spanish
|
| |
• Contextual Key Terms Automatically Extracted for
Each Document
|
| |
|
| |
|
|
 |
| |
|
|
| Turning
content into valuable resources |
|
| |
|
|
| |
|
|
|
