Content is Not King - Context
is!
|
No
longer is the issue content, we have more
content than we know what to do with. The issue
is understanding and knowing the contextual
relevance of all of that content. And, how to
bring relevance to all of that unstructured
data, automatically. Which documents are
Relevant in context of your Now Subject Specific
Informational Need Moment. Consistently
Accurate, In Context, Objectively and
Automatically.
Applying a Bayesian and Heuristic
approach used to be good enough for making
general assumptions of category and loose
subject relevance of unstructured data. Today,
we demand instant, accurate, contextual,
objective and relevant results for the
information we seek from the Yottabytes of
content.
In past, Text Analytic
implementations used statistical inference /
probability approaches (Bayesian / Heuristics)
where lists of keywords and key terms were
compiled per subject matter and then referenced
to iteratively try and determine what a
particular document / data set was about. Those
best-efforts results then used to categorize the
target content. Similar to how some Document /
Content Management Systems work for adding meta
data (tags). Usually though, Content and
Document Management Systems will require Human
Intelligence to first determine how a document
being added to a management system should be
categorized for a more accurate retrieval
purpose.
Let’s hope that Human
Intelligence component isn’t having a bad day or
the best efforts of objectivity goes out the
window.
Statistical inference and
probability approaches were okay, yesterday.
Today, we demand instant,
accurate, contextual, and objectively relevant
results. This requirement would be absolutely
daunting if Artificial Intelligence and Machine
Learning technologies weren’t available! In
fact, the xAIgent (pr: ex-agent) RESTful web
service employs patented AI and Machine Learning
technology to Accurately (83%), Contextually
(per target text), 100 % Objectively (Artificial
Intelligence not Human) and Automatically
provide key phrase and keyword results for
Doc-Tags. The only Automatic, Objective,
Contextually Accurate Document Tagging solution.
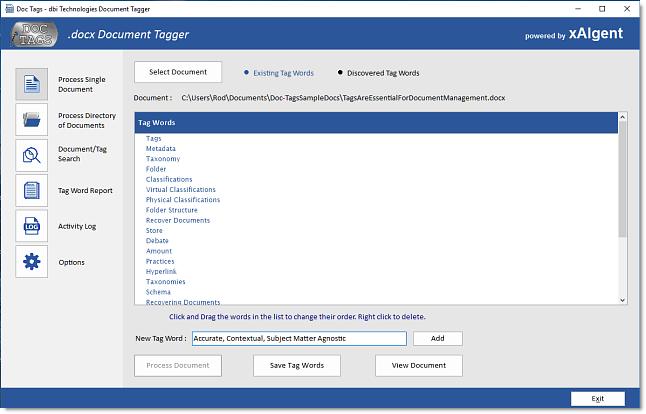
That’s correct. Doc-Tags will
take a Word (.docx) file or text file and
automatically with contextual accuracy, add
keyword and key phrase meta data Tags to the
target file’s Meta Data Tag property.
Doc-Tags is Free to Use for your
first three most accurate document tags. Want
more insight for your document meta data,
increase the number of tags for a small
subscription fee, which will provide up to 30
Contextually Accurate document tags per target
content. |
|
| |
|
|
|
|
|
 |
| |
|
|
| |
|
|
 |
|
|
|
|
| Yesterday will the
be the last day you re-read a document to enter it into
an Enterprise Content Management System. |
| |
| |
|
|
| |
 |
|
|
|
|
|
| |
|
|
|
Feature
Highlights:
|
|
| |
• Automatically Create Contextually Accurate Tags
for a Document
|
| |
• Automatically Create
Contextually Accurate Tags Document Folder
|
| |
• Automatically Add Document Meta Data Tags
|
| |
• Subject Domain
Agnostic - additional training NOT required
|
| |
• Automatic Processing - supervision is NOT
required
|
| |
• Document Tags are presented by Weighted
Importance
|
| |
• Process Reporting ...
|
| |
• Tags Generated
|
| |
• Documents Processed
|
| |
• Document Location
|
| |
• Examine Comparative Document Tags
|
| |
• Find Documents with 'These' Tags
|
| |
• Multi Language Support ...
|
| |
• English
|
|
• French
|
| |
• German
|
| |
• Japanese
|
| |
• Korean
|
| |
• Spanish
|
| |
• Contextual Key Terms Automatically Extracted for
Each Document
|
| |
|
| |
|
|
 |
| |
|
|
| Turning
content into valuable resources |
|
| |
|
|
| |
|
|
|
