Enterprise Content Management
and Doc-Tags
|
Enterprise Content Management systems(ECM) or
Intelligent Information Management systems (IIM)
is the development of strategies, methods, and
tools used to create, capture, automate,
deliver, secure and analyse content and
documents related to organizational process.
There are a number of enterprise solution
providers in this arena - AABBY, Documentum,
Hewlett Packard, IBM, Laserfiche, Microsoft,
Oracle to name a few. Each with their own
perspective and collection of tools that make
their solution the right one.
Organizational process revolves
around structure and their supporting
information including contracts, forms,
agreements and the like, which for the most part
are managed as structured information
(collections of clauses, responses, form-based
data...). How those structured data are
acquired, imputed, processed and consumed is the
foundation of the solutions offered by those
mentioned above and others.
Another basic tenant of
Enterprise Content Management is the employment
of strategies for managing, categorizing and
indexing unstructured content in support of the
organizational processes. A common approach for
giving unstructured content structure is to
employ Tags. Meta Tags, Keywords, Key Phrases -
concise descriptions that can be added to the
profile of the content such as Document Tagging,
which enhances the contextual accuracy for
searching and retrieving content when required.
When unstructured content, a Word
document for instance, is being logged into an
Enterprise Content Management system, if the
person tasked with logging the content is not
the author and the document does not have
author-provided Tags there are only a couple of
options for giving that unstructured content any
resemblance of structure. As long as the
operator has security clearance to view the
content, they can - i) read the document and
define the tags that should be used; ii) use the
document title, first paragraph or synopsis (if
there is one) along with the file name to make a
best efforts guess and select a generic category
item from a pre-defined list of options already
set in the system for categorizing content; or
iii) use a phrase parsing strategy and
referential library (Bayesian / Heuristic
algorithms) to give the content some structure
based on general, pre-defined subject matter
terminology. The latter forms of content
classification are okay, at least they provide
some structure and a better chance that the
content being managed can be retrieved with a
little more accuracy. Of course, the best
possible approach is to have the content author,
the subject matter expert, set the Tags during
preparation. Thus giving the content absolute
contextual, relevant and accurate structural
references.
These somewhat automated
referential approaches rely upon pre-cast,
narrow focus, subject specific referential
libraries - that may or may not relate to the
content being managed. For instance, medical
malpractice is an entirely different subject
matter from bio-tech patent law. Both dealing
with legal matters, however, the subject
terminology of each at different ends of the
spectrum. This is a simple example of where a
generic referential process really doesn't work
and to correct it what would happen is two
specific referential libraries would be created,
each tailored to that branch of law. Not very
efficient.
What about a fourth option, where
an understanding of the construct of human
language is employed allowing for the target
content to be parsed, in context of itself, to
reveal a primary set of key phrases? In essence
a process that strips away all of the
conjugative words, the if's, and's, but's..., to
reveal a collection of content specific key
phrases. And, that process compares how many
times each key term is used throughout the
document and the frequency of each relevant term
given a ranking. The highest ranked terms then
used to retrieve the most predominant examples
from the target content of that term's use. A
Key phrase / Keyword extracted summary if you
will. Automatically, without training (no need
for referential libraries), unsupervised, solely
in context of the target content, accurately.
This fourth option is a
patent-backed artificial intelligence and
machine learning based approach available today.
A content specific, key term extraction approach
that relies upon patented Artificial
Intelligence and machine learning technologies
for deriving target document - accurate,
contextual, relevant Tags. This strategy is
baked into Doc-Tags(tm). The only solution
available today providing document specific,
contextually accurate, unsupervised process for
Automatically giving a document or collection of
documents their own file specific Tags.
Now, think of employing Doc-Tags
in an Enterprise Content Management system where
unstructured content can be given its own custom
structure based upon relevant, contextual,
accurate Tags. ECM content now stored, secured,
analysed with the most accurate search and
retrieval possible. Test Drive It Today.
Accurate, Contextual, Relevant -
Unsupervised, Automatic - Document Tagging |
|
| |
|
|
|
|
|
 |
| |
|
|
| |
|
|
 |
|
|
|
|
| Yesterday will the
be the last day you re-read a document to enter it into
an Enterprise Content Management System. |
| |
| |
|
|
| |
 |
|
|
|
|
|
| |
|
|
|
Feature
Highlights:
|
|
| |
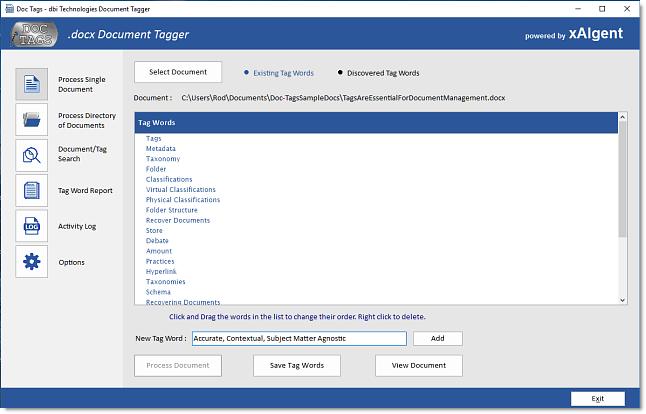
• Automatically Create Contextually Accurate Tags
for a Document
|
| |
• Automatically Create
Contextually Accurate Tags Document Folder
|
| |
• Automatically Add Document Meta Data Tags
|
| |
• Subject Domain
Agnostic - additional training NOT required
|
| |
• Automatic Processing - supervision is NOT
required
|
| |
• Document Tags are presented by Weighted
Importance
|
| |
• Process Reporting ...
|
| |
• Tags Generated
|
| |
• Documents Processed
|
| |
• Document Location
|
| |
• Examine Comparative Document Tags
|
| |
• Find Documents with 'These' Tags
|
| |
• Multi Language Support ...
|
| |
• English
|
|
• French
|
| |
• German
|
| |
• Japanese
|
| |
• Korean
|
| |
• Spanish
|
| |
• Contextual Key Terms Automatically Extracted for
Each Document
|
| |
|
| |
|
|
 |
| |
|
|
| Turning
content into valuable resources |
|
| |
|
|
| |
|
|
|
